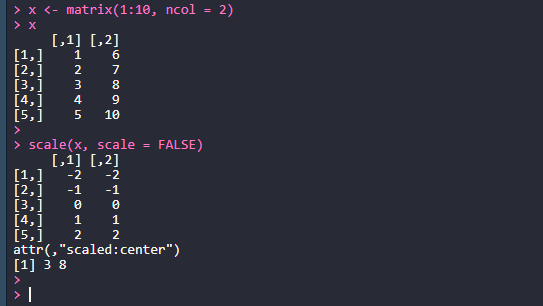
기타 많이 쓰이는 함수 scale( ) : 중심화 > x scale(x, scale = FALSE) subset( ) : 원소의 일부 선택 > subset(airquality, Temp > 94, select = c(Ozone, Temp)) sample( ) : 샘플링 > sample(c(1:10), 5) match( ) : 일치하는 원소 추출 > intersect intersect(1:10, 7:20) which( ) : 조건을 만족하는 원소의 인덱스 > which(LETTERS == "R") choose( ) : 조합의 수 > choose(5, 2) > for (n in 0:10) print(choose(n, k = 0:n)) any( ) : 원소 중 임의의 한 원소 (하나라도 있으면 TRUE, 없으..