주관적 확률은 분석가의 믿음을 나타낸다.
그러므로, 자신의 믿음의 크기를 상대방에게 주지 시키기 위해서는 '높다', '낮다', '많다', '적다' 같은 단어를 이용한 표현보다는 명확하게 '85점', '40점', '70% 이상', '30% 이하'와 같이 숫자를 이용하여 표현하는 것이 좋다.
주관적 확률은 누구나 이해할 수 있지만 충분히 사용되지 않고 있습니다. 우수한 데이터 분석가는 뛰어난 전달자입니다. 주관적 확률은 여러분의 생각과 믿음을 다른 사람에게 정확하게 전달하는 계목적인 방법입니다."
-- p.247
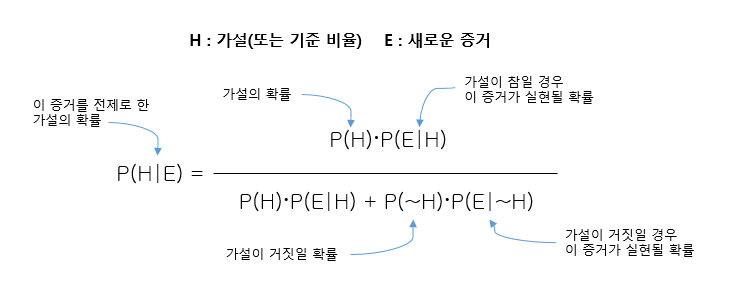
음... 베이즈 정리를 다시 리마인드~
베이즈 정리와 주관적 확률을 사용하면 가설이 참일 경우 증거가 실현될 확률을 구할 수 있다.
ㅇ 분산(variance)
어떤 확률 변수가 기댓값(어떤 확률적 사건에 대한 평균)으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 값이다.
분산은 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다.
ㅇ 표준 편차(standard deviation)
자료의 산포도를 나타내는 수치로, 데이터 집합의 표준값이 산술 평균에서 얼마나 떨어져 있는지 측정한다.
각 가설의 주관적 확률에 대한 산술 평균으로부터의 표준편차가 클수록, 각 가설이 참일 가능성에 대한 분석 간의 이견이 크다고 할 수 있다.
표준 편차는 분산을 제급근하여 구한다.
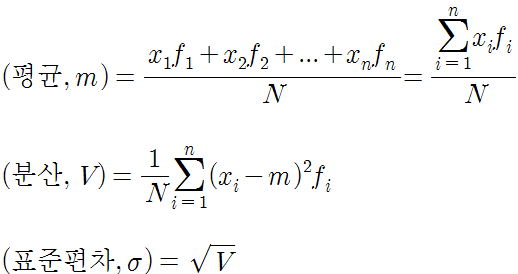
'읽記 (데이터 과학, IT 분야) > Head First Data Analysis' 카테고리의 다른 글
| [HFDA] 9. 히스토그램 / 숫자의 모양 (0) | 2019.11.18 |
|---|---|
| [HFDA] 8. 휴리스틱 분석 / 인간처럼 분석한다 (0) | 2019.11.18 |
| [HFDA] 6. 베이지안 통계 / 첫 걸음을 내딛다 (0) | 2019.11.18 |
| [HFDA] 5. 가설검정 / 그렇지 않다고 말해줘 (0) | 2019.11.18 |
| [HFDA] 4. 데이터 시각화 / 그림은 여러분을 더 똑똑하게 만든다 (0) | 2019.11.18 |