빅데이터 시스템을 구축하기 위한 여러 요소 기술에 대하여 소개되어 있다.
여기서는 여러 요소 기술 중 수집기술, 저장기술, 처리기술에 대하여 소개하고 있다. 빅데이터 수집기술의 종류와 간단한 특징을 소개하고, 빅데이터 저장기술의 유형별 종류와 특징, 빅데이터 처리기술의 종류와 특징도 소개한다.
1. 빅데이터 솔루션 체계
빅데이터 기술의 규정 요소(6V)
| 구분 | 내용 |
| 크기(Volume) | 대량의 데이터(페타바이트 수준) |
| 다양성(Variety) | 정형 데이터 + 반정형 데이터(XML 등) + 비정형 데이터(동영상, 음악 등) |
| 속도(Velocity) | 실시간으로 생성되는 데이터(로그, 대화 내용 등) |
| 진실성(Veracity) | 데이터가 가지고 있는 사실성 혹은 의사결정 연관성 |
| 시각화(Visualization) | 정보 이용자에게 쉽게 보여줄 수 있는 시각화 효과 |
| 가치(Value) | 조직에 제공되는 실질적 가치(비즈니스, 공공정책, 방향성 제시 등) |
2. 빅데이터 수집 기술
빅데이터 수집 기술은 조직 내외부의 여러 데이터를 효과적으로 수집하는 기술이다. 과거에는 데이터베이스를 통해 수집, 정제, 변환 과정을 거치는 정형 데이터 중심이었으나 비정형 데이터가 등장함에 따라 대용량 수집과 저장을 위한 자동화 기술이 요구된다.
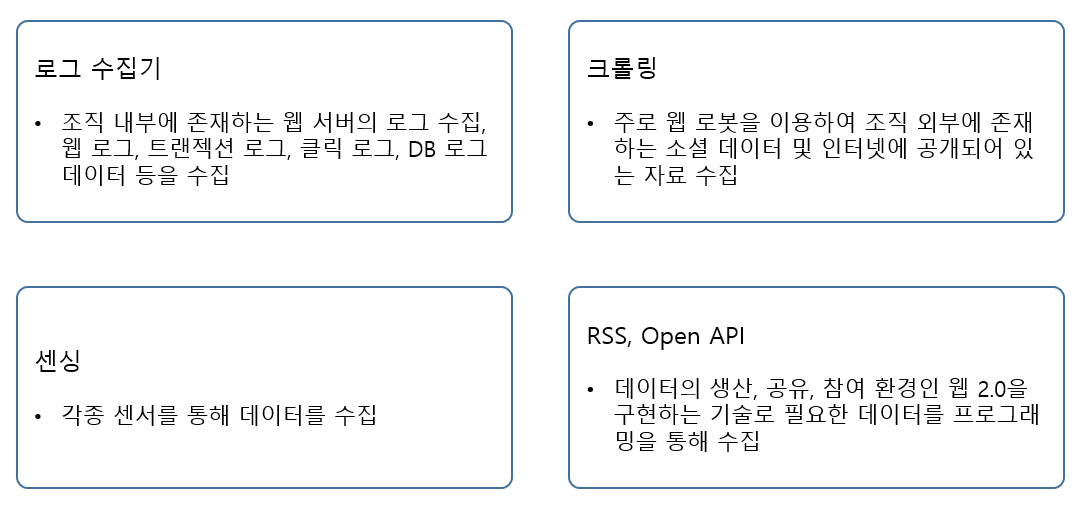
로그 수집기
Splunk
스플렁크는 서버 발생 데이터를 비롯 애플리케이션 데이터, 로그와 리소스 사용량, 메시지, 이벤트 등의 데이터를 실시간으로 인덱싱하고 조회한다.
| 주요 기능 | 내용 | |
| 수집 | · 모든 IT 데이터 수집 지원 · 다양한 수집 방식 지원 |
· 필요 시 별도의 Agent 지원 · 수집 데이터 필터링 기능 지원 |
| 인덱싱 | · 모든 비정형 데이터까지 처리 · 별도의 파서 / 스키마가 필요 없음 |
· 별도의 RDBMS가 필요 없음 · 분산 환경의 대용량 처리 |
| 분석 | · 강력한 상관관계 분석 · 관리를 위한 Lookup 지원 |
· Common Information Model · 다양한 검색 명령어 지원 |
| 대시보드 보고서 | · 사용자 정의의 대시보드 · 고급 U/I를 위한 확장 기능 |
· 실시간 알람 / 경보 발생 · 다양한 보고서 생성 |
Flume
플룸은 데이터를 수집하여 하둡 파일 시스템(HDFS : Hadoop Distributed File System)에 저장하는 자동화 툴이다. 또한 로그 수집기로서 수많은 서버에 분산된 로그 데이터를 한 곳(HDFS)에 모은다.
| Flume의 3요소 | 내용 | 기능 |
| Source | 로그 데이터, stream, socket, DB, file 등의 데이터 소스 | 외부 데이터의 Input |
| Channel | Source로부터 받은 데이터를 sink(target)로 넘기기 전에 데이터를 쌓아 두는 곳으로, 트랜잭션의 보장을 위한 임시 저장 공간 | Source와 Sink의 연결 고리 대량 데이터의 유입 버퍼 |
| Sink | Target(HDFS 저장소나 다른 에이전트)으로 보내는 역할 | 외부 저장소로의 Output |
채널은 수집, 변경된 데이터를 안정적으로 싱크와 연결하고 이동을 지원한다.
| Channel의 종류 | 내용 |
| 채널 셀렉터 | 가장 기본적인 채널로 테이터를 하나 이상의 채널로 이동시키는 역할 수행 |
| Replicating 채널 샐렉터 | 하나의 복사본을 각각의 채널에 넣는 복제 기능 수행 |
| Multipexing 채널 셀렉터 | 헤더 정보를 기반으로 서로 다른 채널로 쓰는 분산 기능 수행 |
Scribe
스크라이브는 Facebook이 개발하여 공개한 스트림 로그 데이터 통합 서버다. 스크라이브는 대량의 서버로부터 실시간으로 들어오는 로그 데이터를 효과적으로 저장하고자 개발되어 대규모 노드 구성을 통해 확장할 수 있다.
웹 크롤링
봇(bot), 웹스파이더 등으로 불리는 웹크롤러를 통하여 웹 정보를 브라우징하여 해당 링크 정보를 모아 저장한다.
웹크롤러는 스게줄러를 통해 리스팅된 URL의 웹 페이지를 내려받아 유효성 검사 후 파싱을 통해 텍스트 정보와 메타 정보를 저장하고, 파싱중에 나온 링크를 다시 리스팅하고 스케줄링하여 일정 수준까지 반복하여 확인한다.
| 웹 크롤러 | 내용 |
| 너치 | 아파치 오픈소스 계열의 웹 클롤러. 웹 수집 및 인덱싱을 지원하며 너치를 통해 사용자만의 검색 엔진을 만들 수 있다. |
| 솔라 | 루센의 가장 상위 검색 플랫폼이다. 너치를 통한 인덱싱을 지원한다. 솔라는 여러 형태의 데이터 검색을 지원한다. 검색 형태는 웹 페이지, full-text search 등이다. |
| 루센 | 루센은 자바로 개발된 고성능의 full-text 검색 엔진 라이브러리다. 루센은 순위 검색과 여러 형태의 쿼리, 다중 인덱스 검색 들을 제공한다. |
Open API
다양한 서비스와 데이터를 좀더 쉽게 이용할 수 있도록 공개한 개발자를 위한 인터페이스를 말한다.
센서 데이터 수집
각종 사물에 센서와 통신 기능을 내장하여 직접 인터넷에 연결, 데이터를 주고 받을 수 있는 IoT 기술의 발전, 전파를 이용해 먼 거리에서 정보를 인식 할 수 있는 RFID 기술의 발전 등으로 다양한 센서의 데이터를 수집할 수 있다.
3. 빅데이터 저장 기술
NoSQL 기반의 데이터 저장 기술, File System 기반의 저장 기술, 클라우드 기반의 저장 기술, 네트워크 기반의 저장기술
| 구분 | 빅데이터 저장 기술 | 내용 |
| NoSQL | Hbase, Cassandra | Key-Value, 컬럼 기반으로 비정형, 반정형 데이터를 저장하는데 유리 |
| File System | GFS, HDFS | 가장 일반적인 데이터 저장 형태, 대용량 데이터의 읽기 위주 작업에 유리 |
| Clud | S3, Open Stack | 인프라와 소프트웨어, 플랫폼을 사용량에 따라 비용을 지불하며 이용 |
| Network | SAN, NAS | 파일 공유형태로 안정성, 신뢰성이 높고, 유연성, 확장성, 편의성이 뛰어남 |
RDB와 NoSQL의 비교
| 구분 | RDB | NoSQL |
| 도입 용이성 | 변경 및 설치 용이 | 기존 Data 재구축 |
| 데이터 | 정형 데이터 처리에 유리 | 비정형, 반정형 데이터 처리에 유리 |
| 성능 | 대용량 처리 시 성능 저하 | 대용량 처리 지원 |
| 비용 | 고가 스토리지와 서버 지원 | PC급 범용 하드웨어 |
| 스키마 | 고정된 스키마 | 비고정 스키마 |
| 사례 | MySQL, Oracle 등 | Big Table, Cassnadra 등 |
DAS, NAS, SAN의 비교
| DAS | NAS | SAN | |
| 구성 요소 | 애플리케이션 서버, 스토리지 | 애플리케이션 서버, 전용 파일 서버, 스토리지 | 애플리케이션 서버, 스토리지 |
| 접속 장치 | 없음 | 이더넷 스위치 | 파이버 채널 스위치 |
| 스토리지 공유 | 가능 | 가능 | 가능 |
| 파일 시스템 공유 | 불가능 | 가능 | 불가능 |
| 파일 시스템 관리 | 애플리케이션 서버 | 파일 서버 | 애플리케이션 서버 |
| 접속 속도 결정 요인 | 채널 속도 | LAN과 채널 속도 | 채널 속도 |
| 특징 | 소규모의 독립된 구성에 적합 | 파일 공유를 위한 가장 안정적이고 신뢰성 높은 솔루션 | 유연성, 확장성, 편의성이 가장 뛰어남 |
HDFS와 Object Storage의 차이점
| 구분 | HDFS | Object Storage |
| 메타 데이터 | Name Node 중심의 중앙 집중형 | 클러스터 복제의 분산 저장 |
| 멀티 테넌시 | 멀티 테넌시 고려 사항 아님 | 멀티 테넌시 기반 |
| 데이터 | 처리 중심의 대용량 데이터 | 용량 크기는 상관없음 |
| 쓰기 작업 | 한 번의 쓰기 작업 | 여러 번 쓰기로 마지막 데이터가 중요 |
| 개발 언어 | Java | Python |
4. 빅데이터 처리 기술
빅데이터 처리에는 크게 다음의 두 가지가 있다.
- 대용량 데이터베이스에서 쿼리를 통해 결괏값을 얻는 방법
- 실시간 처리로 결괏값을 얻는 방법
실시간 처리 비교
| 구분 | CEP(Complex Event Processing) | ESP(Event Streaming Processing) |
| 내용 | Complex라는 시간적 혹인 연관 관계가 존재하는 이벤트를 처리하는 방식 | CEP보다 훨씬 유동적인 연속 streaming의 흐름을 처리하는 방식 |
| 복합 이벤트의 분석을 통해 패턴에서 중요 정보를 제공 | 실시간 이벤트 데이터의 빠른 분석을 통해 정보를 제공 | |
| 수직적 확장 (Scale-Up) | 수평적 확장 (Scale-Out) | |
| 다양한 이벤트 분석이 중요 | 실시간 분석이 중요 |
Esper
java로 개발된 CEP엔진이다. Esper 엔진은 일반적인 데이터베이스가 변경된 형태다. 데이터베이스에서는 데이터를 우선 저장하고 쿼리를 통해 원하는 데이터를 추출하는 반면, Esper는 필요한 쿼리를 애플리케이션에 먼저 등록하고, 데이터를 추출한다. 이러한 실행 모델로 실시성 확보가 가능하다.
Esper는 SQL과 유사한 EPL(Event Processing Language)을 통해 쿼리문을 작성한다. SELECT, FROM, WHERE 절 등이 있다. SQL의 행(ROW)은 EPL에서 이벤트가 되고, SQL에서의 테이블은 EPL에서 이벤트 스트림이 된다.
S4
S4는 Simple Scalable Streaming System의 준말로 Yahoo에서 개발한 MapReduce 모델의 영향을 받은 분산 스트리밍 처리 플랫폼이다.
S4의 주요 설계 목표와 내용
- 간략화 : 데이터 스트림 처리를 위한 간단한 프로그래밍 인터페이스 제공
- 고가용성 : 범용 하드웨어 기반의 수평 확장 가능
- 최소 지연 : 디스크 I/O 최소화와 로컬 메모리 사용을 통한 지연 최소화
- 분산 및 대칭 : 모든 노드의 동일한 기능과 역할, 특정 노드로의 집중화 방지
- 장착형 아키텍처 : 일반적이고 커스터마이징 가능한 장착형 아키텍처
- 설계방법론 지향 : 쉬운 프로그램과 유연성 제시
S4의 용어
| 구분 | 세분 | 내용 |
| Platform | Node | 특정 작업을 수행하는 하나의 인스턴스를 지칭. 소프트웨어적인 개념 |
| Cluster | 실제 작업이 이루어지는 하드웨어를 지칭 | |
| Application | PE (Process Element) |
작은 수행단위로 들어오는 데이터를 처리하고 다음 PE로 보내는 작업 수행 Hadoop의 MapReduce 혹은 Storm의 Spout, Bolt의 개념 |
| Event | 실제로 전송되는 데이터. Key를 가지고 있으며 생성 시간을 자동으로 기록 | |
| Stream | PE와 PE가 주고받는 Event의 흐름을 의미 | |
| Adapter | 외부 Stream을 내부 Application에 전달하는 PE를 지칭 |
Storm
Storm은 트위터에서 개발한 스트리밍 데이터 처리를 위한 신뢰성 기반의 분산 Fault-Tolerant 시스템이며, S4와 많이 유사하다.
Storm의 모듈 구성
| 구성 | 내용 |
| Nimbus | 마스터 노드에서 실행되는 데몬으로 클러스터에 대한 코드 분산, 각 Worker 노드에 대한 작업 할당과 장애에 대한 모니터링 수행 Hadoop의 JobTracker와 유사 |
| Supervisor | 워커 노드에서 실행되는 데몬으로 실제 워커 프로세스들의 실행을 담당 하나의 토플러지는 여러 워커 노드들에 걸쳐 실행될 수 있음 |
| Zookeeper | 메타 데이터 저장을 담당하며 Nimbus와 Supervisor의 상태 관리 수행 Nimbus와 Supervisor 간의 모든 통신 중계 역할 수행 |
| ZeroMQ | 비동기 메시지 전송 계층으로 일종의 임베디드 네트워크 라이브러리 소켓 라이브러리와 TCP보다 빠른 전송으로 비동기 I/O를 수행 |
| Worker | Supervisor에 의해 실행되며, Config에 의해 지정된 포트에서 실행 |
| Task | Worker에서 스레드로 실행되는 Spout나 Bolt의 인스턴스 |
Storm의 기본 인스턴스
- Spout : 스트림의 소스며 Log, API 호출, 이벤트 데이터, 큐 등을 읽어들이는 역할
- Bolt : 스트림을 받아 새로운 스트림에 제공. 스트림 조인, API, 필터, DB 연결, 집계 등의 수행
2019/11/26 - [공부하記/빅데이터 시스템 구축 가이드] - [빅데이터] 4. 빅데이터 시스템 구축을 위한 요소 기술(2)
'읽記 (데이터 과학, IT 분야) > 빅데이터 시스템 구축 가이드' 카테고리의 다른 글
| [빅데이터] 5. 빅데이터 처리와 저장의 핵심 기술, 하둡과 NoSQL (1) (0) | 2019.12.08 |
|---|---|
| [빅데이터] 4. 빅데이터 시스템 구축을 위한 요소 기술(2) (0) | 2019.11.27 |
| [빅데이터] 3. 빅데이터 시스템 아키텍처(2) (0) | 2019.11.24 |
| [빅데이터] 3. 빅데이터 시스템 아키텍처(1) (0) | 2019.11.22 |
| [빅데이터] 2. 빅데이터 구축 방법 (0) | 2019.11.20 |