하둡과 NoSQL에 대한 소개가 있는 장이다. 제법 많은 페이지를 할당해 소개하고 있어 앞선 3, 4장과 같이 파트를 나눠서 기록하려 한다.
1. 하둡이란 무엇인가?
하둡(Apache Hadoop, High-Availability Distributed Object-Oriented Platform)은 데이터가 늘어날 수록 대용량 저장소와 빠른 처리를 위한 고성능을 요구하는 수직적 확장방식의 중앙집중식이 아니라, 다수의 범용 컴퓨터들로 분산하여 저장하고 처리하는 수평적 확장방식의 분산처리 플랫폼이다.
하둡은 빅데이터 처리를 보장하는 검증된 플랫폼이다. 하둡은 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크이다.
원래 너치(Apache Nutch)의 분산 처리를 지원하기 위해 개발된 것으로, 아파치 루씬(Lucence)의 하부 프로젝트이다. 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템(HDFS: Hadoop Distributed File System)과 맵리듀스(MapReduce)를 구현한 것이다.

HDFS(Hadoop Distributed File System) 대용량 데이터의 분산 저장을 위한 파일시스템
MapReduce 구글에서 분산 병렬 컴퓨팅으로 대용량 데이터를 처리하기 위한 목적으로 제작하여 2004년 발표한 소프트웨어 프레임워크
루씬(Lucence) 자바 언어로 이루어진 정보 검색 라이브러리 자유-오픈 소스 소프트웨어이며, 더그 커팅에 의해 개발되었다. 웹 검색엔진 및 단일 로컬 사이트 검색 구현에 유용성이 있으며, 편집 거리를 기반으로 퍼지 검색을 수행하는 기능을 포함한다.
너치(Apache Nutch) 루씬을 기반으로 하여 만든 오픈 소스 검색 엔진이다. 루씬을 기반으로 하였지만 웹 크롤러는 처음부터 다시 만들었다. 여러 가지 플러그인을 붙일 수 있도록 모듈화가 잘 되어 있다. 현재 아파치의 하위 프로젝트이다.

하둡의 버전과 발전
하둡은 0.x로 시작된 개발용 버전에서 출발하여, 0.18 → 0.19 → 0.20 → 0.20.2 → 0.20.205 → 1.0 순서로 발전한 1.X의 버전과 0.23 버전에 YARN(Yet Another Resource Negotiator) 아키텍처가 추가되어 발전한 2.x 버전으로 나뉜다.
2.x의 HDFS에 삭제 코드를 추가하여 저장 공간을 줄이고, YARN v.2로 자원관리를 향상시킨 3.x 버전이 있다.

1.x와 2.x의 비교
| 구분 | 1.x | 2.x |
| 노드 수 | 클러스터당 4,000노드 제한 | 클러스터당 10,000노드 확장 |
| Job Tracker 병목 | Job Tracker가 리소스 매니지, Job Scheduling, 모니터링 등을 모두 수행 | Job Tracker를 리소스 매니저와 애플리케이션 마스터로 분리 수행 |
| SPOF | HDFS에 오직 하나의 Namespace 존재 | HDFS 관리를 위한 다수 Namespace 지원 |
| 자원 활용성 | Map과 Reduce의 개별 수행으로 리소스 낭비 | Map과 Reduce가 별도 슬롯 없이 컨테이너 안에서 수행 |
| 호환성 | MapReduce만 수행 | MapReduce 외의 다른 분산 시스템 지원(STORM, HANA, GIRAPH 등) |
JobTracker 하둡 처리 사항을 받아 클러스터의 특정 노드에 MapReduce 작업을 수행하게 하고 관리하는 하둡 내 서비스
TaskTracker JobTracker로부터 Map, Reduce, Shuffle 등의 작업을 받아 처리하는 클러스터 내 노드
Job Scheduling 어떤 작업부터 시스템 내의 자원들을 실제로 사용할 수 있도록 할지를 결정한다. 작업들이 시스템에 들어오는 것을 승인하는 것이기 때문에 승인 스케쥴링(Admission Scheduling)이라고도 한다.


하둡의 특징
하둡은 병렬 확장으로 대량의 데이터를 빠르게 처리한다. 즉, 수평적 확장으로 분산 저장된 데이터를 처리하며, 확장할 때는 기존 High-End급 서버와는 달리 저가의 Low-End급 서버를 이용한다.
저가 하드웨어, 중복 저장, 자동 복구 등 기존 시스템과 다른 특징이 있다.

하둡 프레임워크 - HDFS
데이터를 저장하는 파일 시스템과 데이터를 처리하는 모듈로 이루어진다. 하둡의 파일 시스템이 HDFS이고 데이터 처리 프로세스가 MapReduce다.
HDFS는 Master/Slave 아키텍처를 가지고 있으며, 모든 파일 정보는 Master의 Name Node가 가지고 있다. 그 밑 하위의 Data Node는 파일 저장과 노드 간 복제를 수행한다.
| 구분 | 설명 |
| Name Node | 파일 시스템의 메타 데이터(파일 정보, 디레터리 구조, 접근 권한 등) 관리 |
| 하나의 namespace와 메타 데이터를 가짐 | |
| Data Node와 주기적으로 통신하여 상태 확인 | |
| 속도를 위해 Memory에서 수행 | |
| SPOF(Single point Of Failure) | |
| Data Node | 실제 데이터 블록의 고정 크기로 저장하고, 노드 간 복제 수행 |
| 기본 3곳의 Data Node에 복제 수행 | |
| Name Node에 주기적인 상태 보고 |


하둡 프레임워크 - MapReduce
하둡 프레임워크의 하나인 MapReduce는 대용량 파일을 처리하는 핵심 엔진이다. MapReduce는 데이터를 종류별로 나누고, 중복을 제거하여 분산 처리하는 병렬 데이터 처리 프레임워크다.

- Map : 비정형 데이터를 입력받아 Reduce에서 정형화된 포맷의 키/값 쌍으로 매핑
- Reduce : Map에서 입력받은 정형화된 키/값 쌍을 실제 병렬 처리하는 모듈

MapReduce는 크게 JobTracker, TaskTracker와 Client Library로 구성된다.
JobTracker와 Taskracker의 역할
| 구분 | 설명 |
| JobTracker | Single 형태로 Master 역할을 하며 Name Node와 같이 위치함 |
| Job 수행을 받음 | |
| Job을 Map과 Reduce 태스크로 분할 | |
| 여러 TaskTracker에게 태스크를 나눠주며 진행 모니터링 | |
| 실패한 태스크에 대한 reschedule 실행 | |
| TaskTracker | 여러 개로 Slave 역할을 하며 Data Node와 같이 위치함 |
| 하층부에서 태스크를 수행 | |
| 진행 사항을 JobTracker에게 보고 |
MapReduce의 작업 처리 과정

MapReduce 처리 작업
| 구분 | 설명 |
| Input Dataset | 임의의 상태로 HDFS에 저장된 기가바이트 이상의 원시 데이터 |
| Split | 데이터를 하나의 Map에서 작업할 수 있는 블럭(64MB)으로 나눔 |
| RecordReader | 나뉜 블록을 Map에서 읽을 수 있는 Key/Value 쌍으로 구분 |
| Map Task | 코드 상의 정해진 처리를 위한 Key/value중간 작업을 함, 실제 요구 사항의 논리적 작업을 수행하는 첫 단계 |
| Shuffle | HTTP를 통하여 연관된 파티션(분리된 서브 Set)으로 가져가는 작업 |
| Sort | 키를 통하는 그룹값 |
| Reduce Task | Sort 값들을 필터링, 합치는 작업을 수행하여 최종 key/value를 내놓음 |
| Record Writer | 최종 ket/value를 변환하여 파일로 출력 |
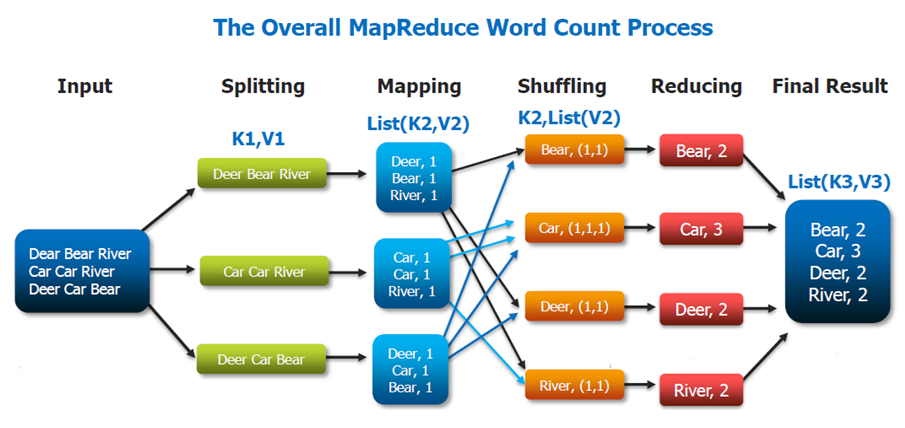

https://0x0fff.com/hadoop-mapreduce-comprehensive-description/

'읽記 (데이터 과학, IT 분야) > 빅데이터 시스템 구축 가이드' 카테고리의 다른 글
| [빅데이터] 5. 빅데이터 처리와 저장의 핵심 기술, 하둡과 NoSQL (3) (0) | 2019.12.20 |
|---|---|
| [빅데이터] 5. 빅데이터 처리와 저장의 핵심 기술, 하둡과 NoSQL (2) (0) | 2019.12.19 |
| [빅데이터] 4. 빅데이터 시스템 구축을 위한 요소 기술(2) (0) | 2019.11.27 |
| [빅데이터] 4. 빅데이터 시스템 구축을 위한 요소 기술(1) (0) | 2019.11.25 |
| [빅데이터] 3. 빅데이터 시스템 아키텍처(2) (0) | 2019.11.24 |